关注过Hadoop+hive+flask+echarts大数据可视化项目的读者,这里是第四部分。前面的部分完成了Hadoop环境的搭建,并把系统收集的相关信息上传到了Hadoop平台中。现在需要搭建hive环境并实现系统数据的分析,后续就会把分析的内容转换接口,返回到前台,并用echarts组件进行图表展示。
hive是一个基于HDFS的MapReduce框架,将HQL转化成MapReduce执行,所以使用hive的前提是已经安装了Hadoop,这是其一,其二,由于HQL语句与SQL语句有着异曲同工之妙,hive的元数据就是存储在sql数据库中,HQL语句和SQL语句基本上是通用的,所以还需要安装mysql服务。其三完成Hive安装之前,需要分布式协调服务zookeeper的支持,Zookeeper 是为分布式应用程序提供高性能协调服务的工具集合,是Hadoop 的分布式协调服务,可以用来保证数据在ZK集群之间的数据的事务性一致。Zookeeper可以为hive提供注册服务,发现服务的功能需求。
由于安装Hadoop之前的连续博文中已经提及到了,这里就不再赘述了。
(1)安装mysql数据库服务器
这里安装的mysql版本为5.7,由于直接安装mysql服务器会报错,因此需要提供mysql服务器的安装源。mysql57-community-release可以提供mysql服务器安装repo安装源,首先需要安装mysql57-community-release文件,由于其是一个rpm文件,因此上使用rpm -ivh来安装mysql57-community-release文件。命令使用如下图所示。
在mysql57-community-release的rpm包安装之后,需要把yum.repos.d中的mysql-community.repo文件修改其中的配置,不然,安装过程可能会报错。需要修改的配置文件如下图所示。


图中的mysql-community.repo就是需要修改的mysql安装的配置文件。使用vi命令编辑此文件,修改其中配置,把mysql57下的gpcheck设置为0,即gpcheck=0。修改操作如下图所示。

如上图所示,repo文件配置修改成功后,就可以安装mysql服务器。直接使用yum install mysql-server即可完成安装,如下图所示。
安装成功后,显示安装成功的界面如下图所示。
mysql服务安装成功后,使用systemctl start启动mysql服务器。
上图中启动的mysql服务名称为mysqld。启动后可以通过systemctl status来查看mysql服务器的启动状态。
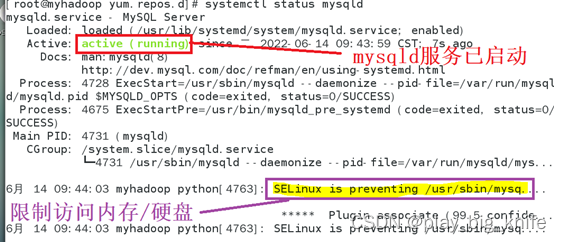
图中有SELINUX限制了访问内存和硬盘,可以把SELINUX禁用。编辑etc目录selinux目录中config文件。文件路径如下图所示。
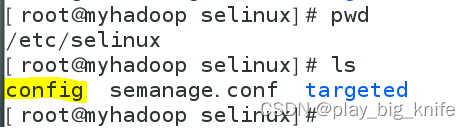
上图中标黄的文件config为需要修改编辑的文件 ,在config文件中编辑禁止SELINUX的相关设置。如下图所示。

这个配置需要重启有效,这里mysqld已启动,完成mysqld的相关设置后,再让SELINUX下次启动失效也可以。
前面提到已启动数据库服务mysqld,启动后其日志存在目录var的log目录下,由于mysql5.7的密码是随机的。随机值通过查询的方法找到。操作方法如下图所示。
上图中标黄的部分为mysql5.7产生的密码。利用产生的密码登录mysql5.7。如下图所示。

登陆成功后使用alter user对数据库中产生的随机密码进行修改,默认修改的初始权限是要满足密码复杂度的,也就是必须有字母、数字和符号。这里设置为“Abcd.1234”。使用的具体命令如下图所示。
因为密码设置的比较复杂,不利于笔者的后期操作,这里把密码改简单一点。先退出mysql,验证使用新密码是否能够正常进入mysql。如下图所示。
重新使用新密码登陆后,需要修改原密码的复杂度,可以先使用show global variables把涉及到密码复杂度的变量全部找出。命令的使用结果如下图所示。
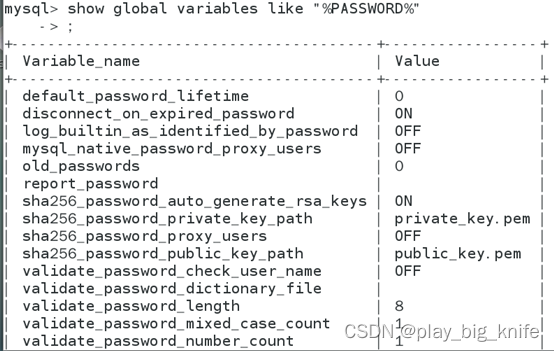
图中显示出关于PASSWORD的全部配置,这里需要把密码长度缩小,也需要把密码等级降为LOW。其对应的两个变量参数解释如下图所示。
首先使用set命令把validatepasswordpolicy修改为“LOW”,命令的使用如下图所示。
接下来,继续使用set来修改密码长度的策略如下图所示。
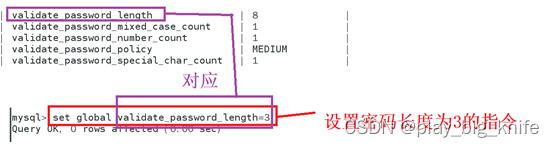
完成密码复杂度的修改后,就可以继续使用alter user来重置用户密码,具体使用如下图所示。

这里把密码改成简单的”admin”。数据库就成功建立。
(2)安装zookeeper分布式协调服务
安装zookeeper的服务直接解压zookeeper的解压包即可,这里首先在usr目录下建立zookeeper目录。命令使用如下图所示。

接下来把上传到home中soft目录下的zookeeper压缩包进行解压,命令使用如下图所示。

解压后的zookeeper服务需要配置后,才能进行启动。配置zookeeper服务需要进入到zookeeper的解压目录,并在目录下找到conf的文件夹,如下图所示。

如上图中找到了conf目录后,进入到conf目录中,在conf目录中预先是不存在zookeeper启动所需要配置文件的,只有一个zookeeper启动配置文件的模板zoo_sample.cfg,如下图所示。

这里可以通过cp拷贝命令把zookeeper的模板先拷贝成zookeeper的配置文件名zoo.cfg。如下图所示。
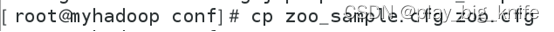
接下来完成zoo.cfg文件的编辑,需要指明zookeeper服务器的IP地址和端口,可以通过下面的语句实现。
上面语句中的3888端口号是用户自己定义的任意端口号。
如下图所示。
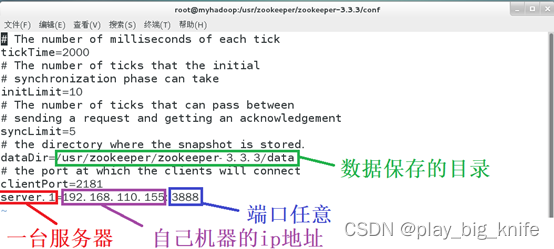
图中除增加了一台服务器的设置外,还将配置中dataDir的数据保存目录做了修改,将目录修改为zookeeper工作目录下的data目录。现在需要在data目录下建立myid的文件,表征zookeeper中提供服务的不同服务器名称。具体命令使用如下图所示。

图中最后的vi myid命令就是实现myid文件的编辑,因为只有一台服务器,myid的内容这里设置为1。myid文件内容设置如下图所示。
图中把myid的内容设置为1。
zookeeper设置成功后,可以在zookeeper工作目录下的bin文件夹中启动zookeeper。如下图所示。
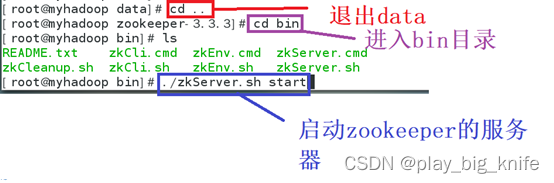
启动zookeeper成功有STARTED标志。如下图所示。
然后使用jps查看进程信息,会出现QuorunPeerMain进程名,如下图所示。
(3)配置hive
Hive的安装也是需要解压hive的安装包,解压后完成hive配置文件的修改。
首先在usr目录下建立hive的文件夹,操作命令如下图所示。

接下来把上传到机器软件目录中的hive解压包解压到当前usr下建立的hive目录中。具体解压命令如下图所示。

然后,需要进入到hive的工作目录中,可以看到hive的配置目录conf,如下图所示。

进行到conf目录后,需要对一些重要配置文件进行配置。这里需要配置conf目录下的两个文件,如下图所示。

由于hive启动的环境配置文件名为hive-env.sh,原有的配置目录conf下面是没有hive-env.sh,需要把hive-env.sh.template模板文件更名为hive-env.sh。使用cp指令完成模板文件的拷贝同时把产生的新文件更名。如下图所示。
完成cp指令后,首先编辑hive-env.sh文件,使用vi指令完成环境配置文件的修改,如下图所示。

在hive-env.sh文件中需要指明Hadoop的工作路径和hive配置文件conf的目录所在。具体修改内容如下图所示。
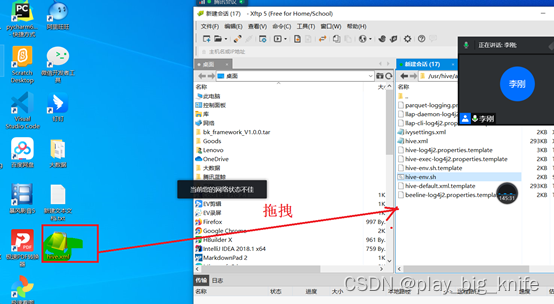
编辑完hive-env.sh后,需要继续编辑hive-site.xml文件,由于hive-site.xml中文件配置项太多,这里通过xftp软件先下载到windows本地系统中去修改。下载方式如下图所示。
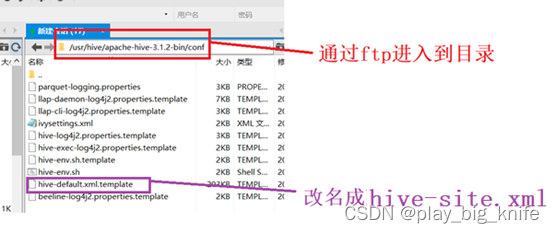
由于原有的conf目录下没有hive-site.xml,需要把hive-default.xml.template拖拽到桌面,如下图的详细指示。
拖拽后,再更名为hive-site.xml,修改即可。

文件拖拽到桌面后,用记事本工具打开该文件,搜索数据库方面的设置进行修改,这里可以搜索“javax.jdo”。如下图所示。
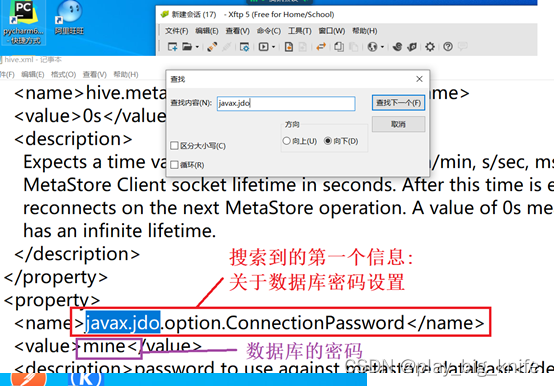
如上图,通过搜索,搜索到的第一个配置项为javax.jdo.option.ConnectionPassword,其内容表征了连接数据库的密码,这里设置成“admin”,为前面安装mysql数据库时设定的密码。如下图所示。
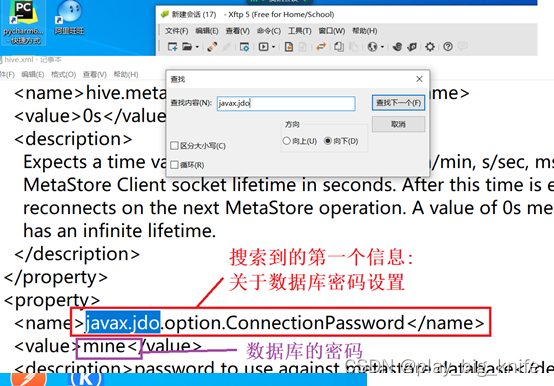
接下来继续搜索“javax.jdo”,搜索到第二个配置项如下图所示。
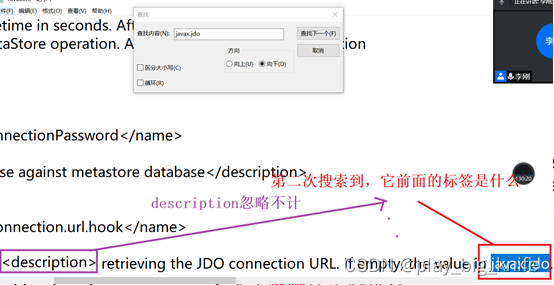
上图中显示第二个查询到含有“javax.jdo”内容的语句在description当中,由于description是表示“描述”的意思,因此上当前搜索到的javax.jdo是需要忽略不计的。
持续在文档中搜索“javax.jdo”内容,根据连接数据库配置的要求,当搜索到javax.jdo.option.ConnectionURL,也就是指定连接地址选项时,需要修改参数,在这个搜索期间,不管你遇到了什么元素,都不属于基本数据库配置修改的范畴,这里不用去理会。对javax.jdo.option.ConnectionURL的修改内容如下图所示。
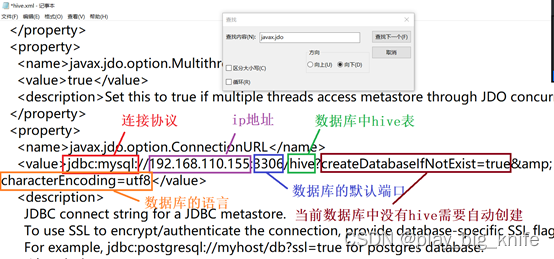
由图中可以得到,其value值指定了mysql连接的ip地址192.168.110.155,数据库mysql连接的端口号为3306,需要连接的数据库名称为hive,当数据库不存在时需要自动创建数据库则指定参数createDatabaseIfNotExist=true,使用的编码格式为characterEncoding=utf8。这样连接数据库的value值就构成了下面的地址:
上面地址中的jdbc:mysql指的是协议的名称。
修改完连接地址后,继续查找“javax.jdo”内容,当搜索到javax.jdo.option.ConnectionDriverName选项时,也就是指定连接的驱动名称,这里使用com.mysql.jdbc.Driver。后续会把mysql连接java的jar包也拷贝到hive工作目录的lib目录中。这里指定的驱动名称也是jar包中指定的名称。具体配置项的修改如下图所示。
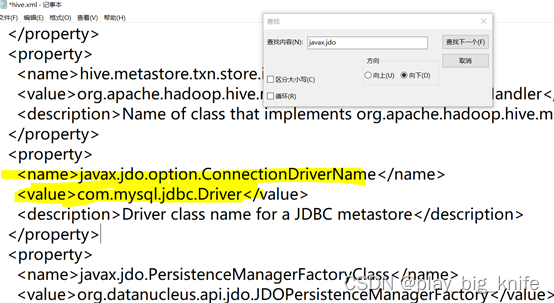
继续在文档中搜索,当搜索到javax.jdo.option.ConnectionUserName,也就是需要设置数据库的连接用户名,这里需要把用户名修改成登陆数据库的用户名,使用root。具体设置如下。
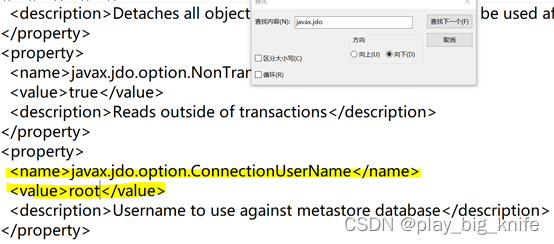
根据java连接数据库的要求,需要提供登陆数据库的用户名,密码,连接地址和驱动,这是java操作数据库jdbc的四个关键要素。
修改配置文件中的四个要素后,把修改的hive-site.xml文件名称再通过ftp拖拽回hive的配置目录中。操作方法如下图所示。
Hive的两个配置文件修改成功后,需要对hive进行初始化后,才可以使用hive。初始化hive的程序保存在hive工作目录的bin目录中。如下图所示目录结构。
进入目录后,在目录中使用schematool进行初始化。初始化指令如下图所示。

俗话说:“达到成功的路有时是曲曲折折的”,在初始化的过程中,可能会出现如下的报错情况。
第一次报错,出现如下图所示情况。
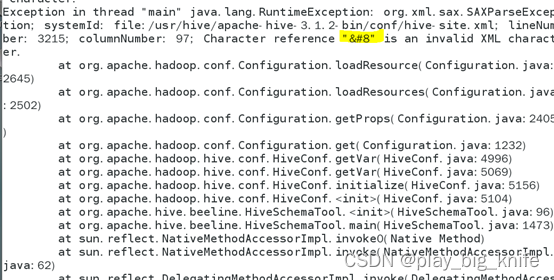
这里指示“”报错。出现如此编码的报错信息需要查找配置文件中出现“”的具体位置,查看一下问题出现的原因。这里可以把windows中桌面上的hive-site.xml文件再次打开,通过搜索来查找“”的位置。查找到的结果如下图所示。

从图中搜索到的位置,可以得知“”出现在标签中,出现在此位置的“”由于编码问题不会承认,那就干脆把这段非法字符删除即可。删除“”标记内容后保存hive-site.xml文件,然后通过ftp回传到hive工作目录的conf目录下。
接下来,再次执行hive的初始化命令。
执行过程中发生的第二次报错,如下图所示。

如图中指示的错误原因,已经明确提出了“com.mysql.jdbc.Driver”驱动没有找到,这里直接把java连接mysql的驱动包上传到hive工作目录的lib目录下即可,具体使用ftp的操作方法如下图所示。
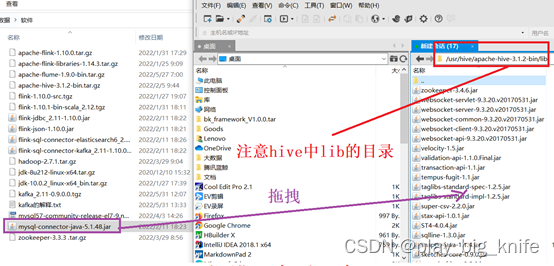
图中把mysql-connect-java的版本为5.1.48的jar包上传到hive工作目录的lib目录中。接下来继续执行hive初始化。再次报错如下图所示。
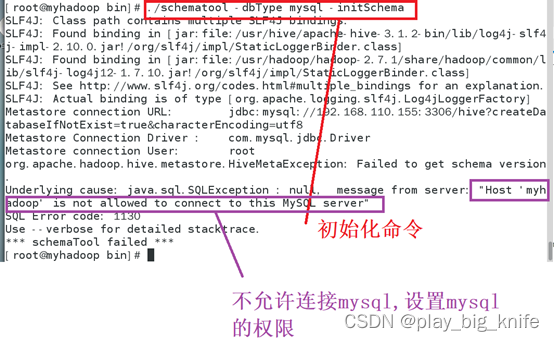
这也是hive初始化的第三次报错,这次报错的原因在于mysql没有开放外部程序hive的连接权限。需要mysql设置hive的连接权限,通过输入进入数据库的指令mysql -u root -p,然后输入数据库的密码,进入数据库后使用grant all指令开放hive连接数据库的权限。具体命令如下图所示。

图中命令开放了所有主机连接数据库root用户的权限,“%”指示了所有的主机,所有主机连接root用户时需要使用的密码是“admin”。下面继续对root的权限进行一下刷新。使用指令如下图所示。

继续执行hive的初始化指令。
执行过程中出现警告,如下图所示。

这里的警告需要在数据库连接中设置useSSL=false。进入到hive-site.xml中,搜索到“javax.jdo.option.ConnectionURL”配置项,将配置项下面的连接地址后面加上“useSSL=false”,如下图所示。

继续执行schematool初始化hive,得到显示信息如下图所示。
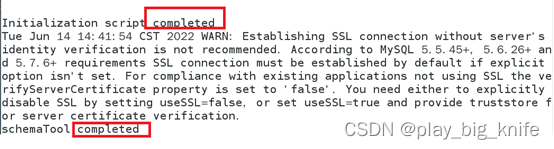
图中显示的的内容“completed”表示初始化成功。
初始化成功后,可以通过hive目录中bin目录下的hive程序来进入hive的操作平台。如下图所示。
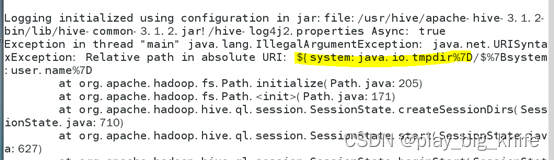
上图所示,在进入过程中发生了错误,错误指示在“${system:java.io.tmpdir”内容处。此处显示了“相对地址在绝对路径中”。这里可以把相对地址转成绝对地址,仍然对hive-site.xml进行操作,打开hive-site.xml文件,查找”java.io.tmpdir”。
通过查找,查询的第一处位置如下图所示。
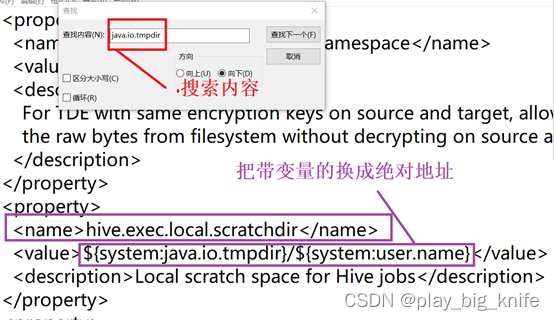
这里可以把java.io.tmpdir的路径成hive目录中的绝对路径,具体修改如下图所示。
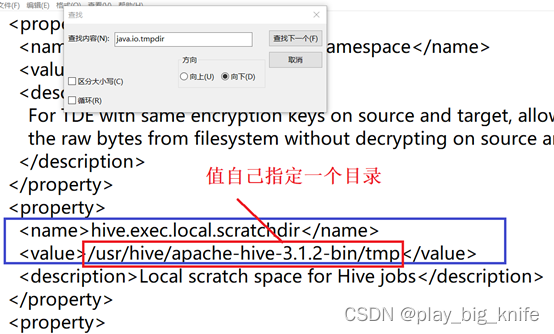
再次查找“java.io.tmpdir”,可以查询到第二处地址如下图所示。
查询到内容后,将其仍然修改为绝对地址,修改内容如下图所示。
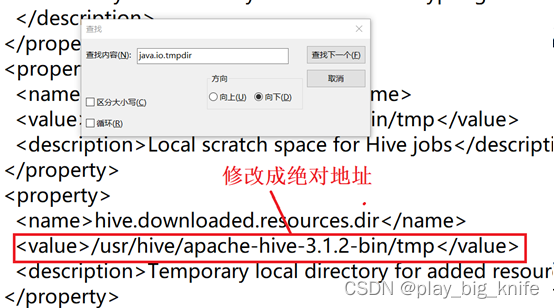
继续查找“java.io.tmpdir”,可以查询到第三处地址如下图所示。
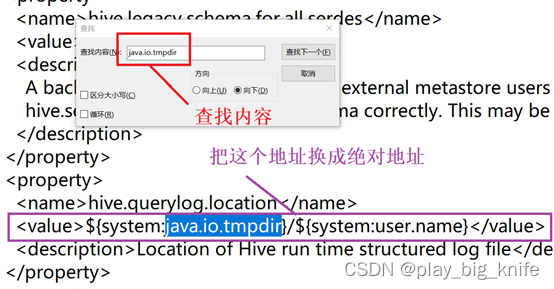
查询到内容后,继续将其仍然修改为绝对地址,修改内容如下图所示。
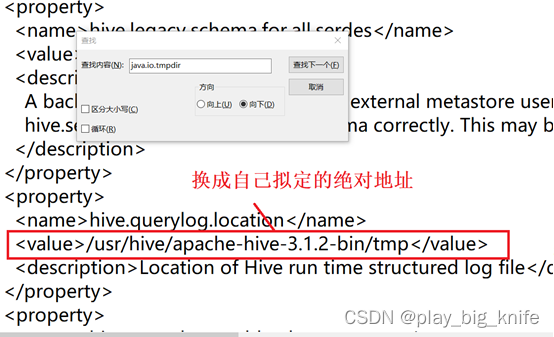
接下来继续查找内容“java.io.tmpdir”,如下图所示。
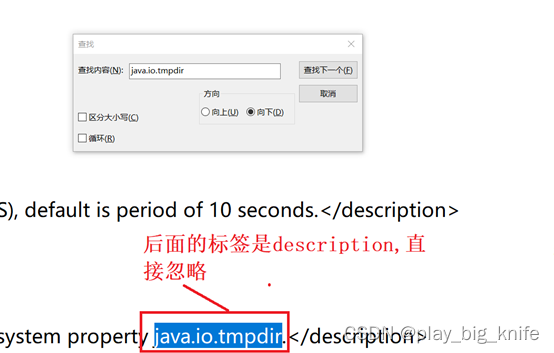
由图中可知,此处内容出现在标签当中,这里对description中的内容可以忽略不计。继续查找“java.io.tmpdir”如下图所示。
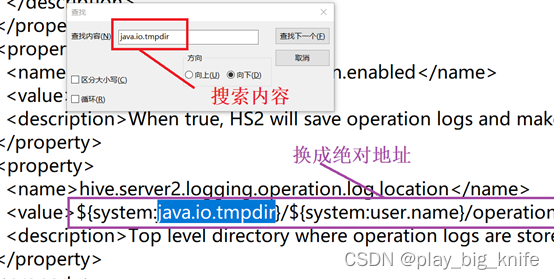
查找到内容后,继续把该项中的value值修改成绝对路径,修改方法如下图所示。
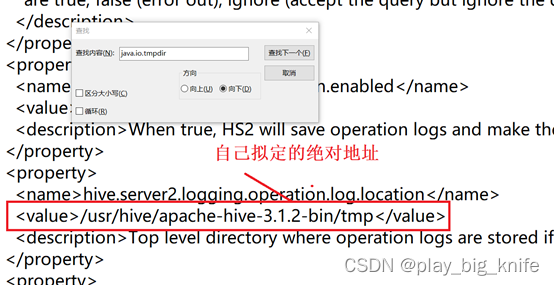
通过修改,一其修改4处关于“java.io.tmpdir”内容的地方,修改成功后,保存,继续通过ftp上传服务器,如下图所示。
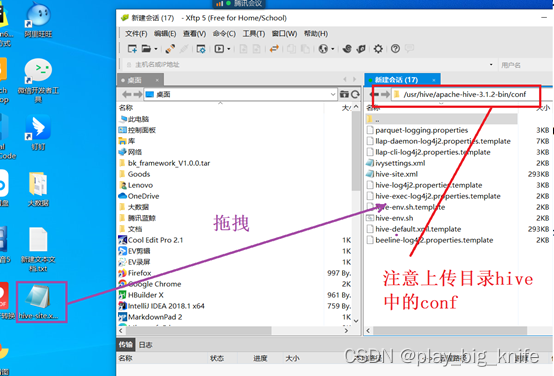
上传服务器中注意hive-site.xml的存放路径,下面继续执行hive程序。如下图所示。
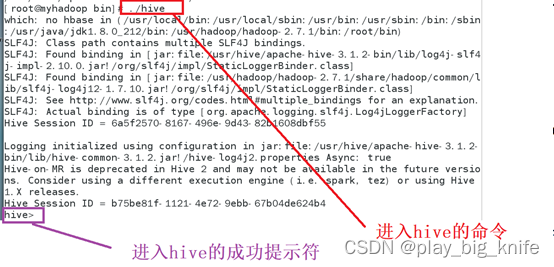
由图中指示可知,此时出现了hive的提示符,表示成功进入hive的工作环境。
此时可以把一段时间内监控的数据上传到hadoop后,通过hive的导入指令导入到hive中。数据内容如下图所示。
这里首先先把数据文件上传到hadoop平台中,可以使用hadoop fs -put指令实现,如下图所示。

将数据导入hive之前首先需要建立表格,hive建立表格的HQL语句与SQL语句类似,不过由于hive的数据是需要从hadoop平台中的文件来导入的,在建立表格时需要指定导入数据文件时每个字段间的分隔符。在system.txt中分隔符是”|”。详细命令如下图所示。

其命令中参数的详细解释如下图所示。

使用导入语句将数据导入到hive环境后,数据就已经分配到了表中,可以使用select语句来查询。如下图所示。
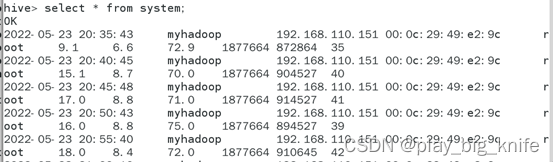
导入hive中的数据可以使用HQL语句进行数据分析。这里对“1小时内的内存使用的峰值。”
单纯从统计内存中的峰值角度出发可以使用group by分组函数,从1小时的时间点出发,group by后面的分组字段以时间为参考,分组后统计最大量通过max()函数实现,收集内存中参数显示的是总量和空闲量,这里可以用量减去空闲量得到最终的使用量。通过分析,可以使用如下HQL语句实现统计。
通过执行可以得到如下图所示的结果。
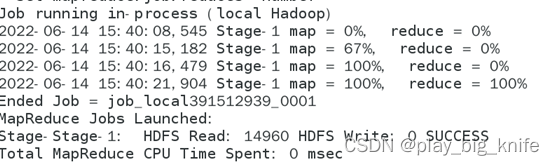
由图中可以得知,select语句会将HQL语句转化成mapreduce过程。
最终得出的分析结果如下图所示。

输出结果中没有指明“小时”的标志,如果需要指明“小时”的标志,需要在select后指明hour函数来使用,具体指令如下图所示。

执行过程中仍然会把HQL语句转化成mapreduce语句,如下图所示的mapreduce过程。
最后查看结果中显示小时的信息,如下图所示。

图中所示的小时数值,后面的数值就是峰值,峰值点在哪个时段段,并没有体现。你只知道在20:00-21:00之间出现的峰值,峰值在哪一个具体的采集时间段产生的,这里并不清楚。用分区方法不但显示1个小时内的峰值,还要峰值在哪一个监控采集时间段。分区使用窗口函数over。
形如over(partition by hour(systemdate)) 每一行根据systemdate系统时间的小时来划分窗口,通地窗口进行分区统计。使用窗口函数来计算1小时内存使用量峰值的命令使用如下图所示。

在窗口分区的过程中也可以进行排序。命令如下图所示。

关于命令的详细解释如下图所示。

执行该条语句,也会使用HQL将其转化成mapreduce程序最终显示的结果中不但包含有每个时间的详细信息,也能对比该时段内是否达到了内存的峰值。如下图所示。

由此分析,可以扩展到“1小时内哪个时间段硬盘使用量最高”,“1小时内小时内哪个时间段cpu的用户使用率最高”等问题。
欢迎关注Hadoop+hive+flask+echarts大数据可视化项目,后续会有持续的精彩。
博客中部分采集的数据可以在github地址中下载:
以上就是本篇文章【Hadoop+hive+flask+echarts大数据可视化项目之hive环境搭建与系统数据的分析思路】的全部内容了,欢迎阅览 ! 文章地址:http://tiush.xhstdz.com/news/4520.html
栏目首页
相关文章
动态
同类文章
热门文章
网站地图
返回首页 物流园资讯移动站 http://tiush.xhstdz.com/mobile/ , 查看更多