课件获取:关注公众号“数栈研习社”,后台私信 “ChengYing” 获得直播课件

视频回放:点击这里
ChengYing开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下海洋同学的直播分享《ChengYing部署Hadoop集群实战》
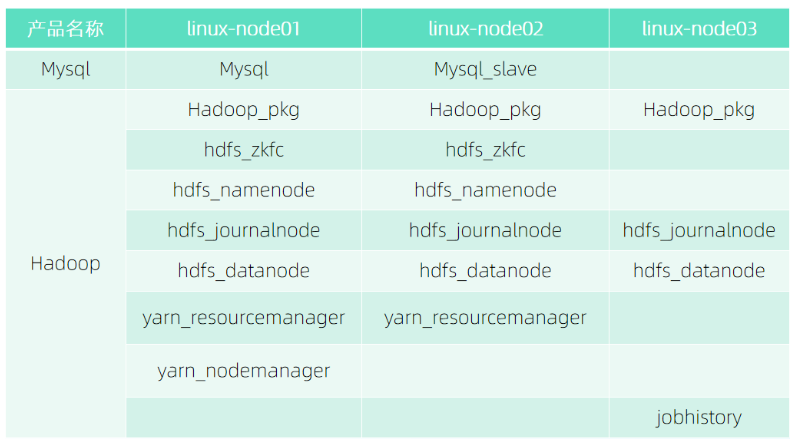
在部署集群前,我们需要做一些部署准备,首先我们需要按照下载Hadoop产品包:
● Mysql
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Mysql_5.7.38_centos7_x86_64.tar
● Zookeeper
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Zookeeper_3.7.0_centos7_x86_64.tar
● Hadoop
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hadoop_2.8.5_centos7_x86_64.tar
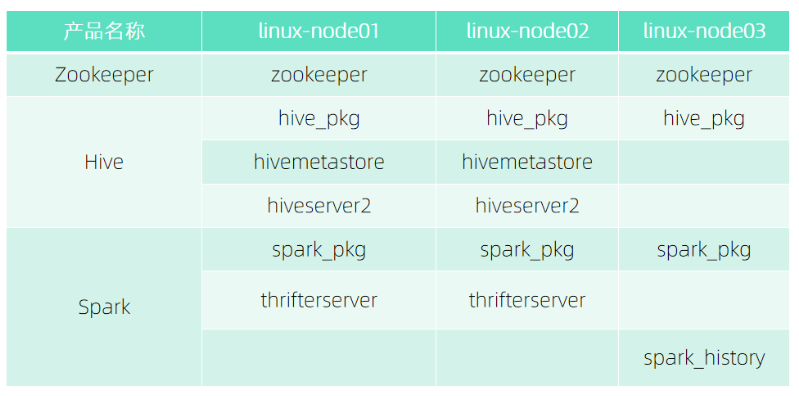
● Hive
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hive_2.3.8_centos7_x86_64.tar
● Spark
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Spark_2.1.3-6_centos7_x86_64.tar
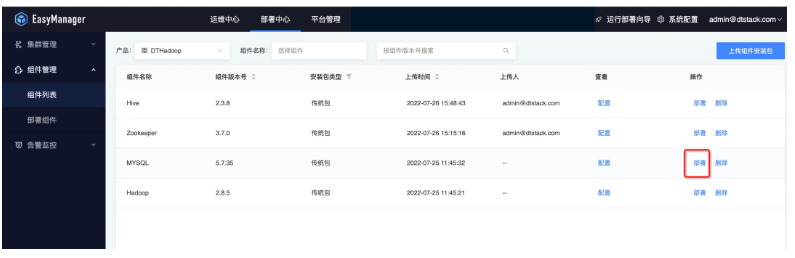
接着我们可以将下载好的产品包直接通过ChengYing界面上传,具体路径是:部署中心—组件管理—组件列表—上传组件安装包:
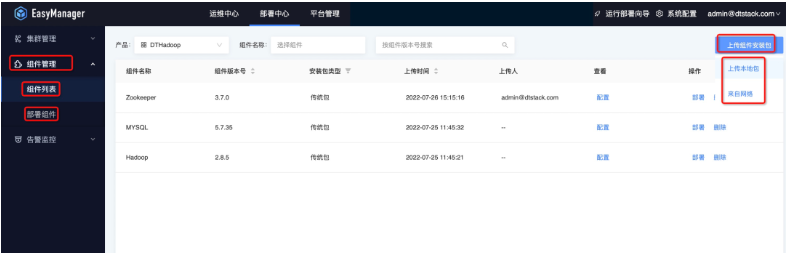
可以通过两种模式上传产品包:
产品包在先下载到本机电脑存储中,点击本地上传,选在产品包上传。
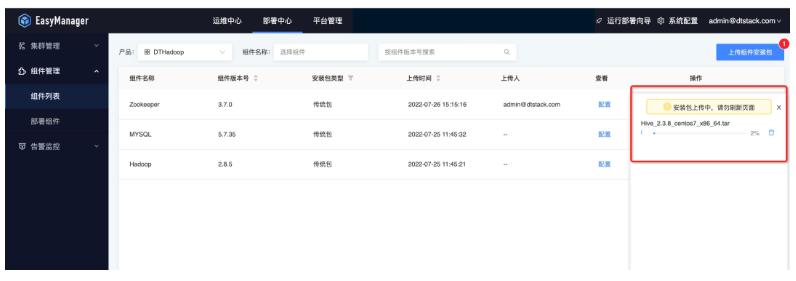
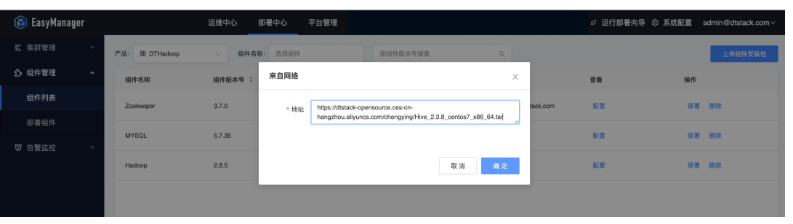
直接填写产品包网络地址上传(ChengYing的网络需要和产品包网络互通)。
做完准备后,我们可以开始进入集群部署,Hadoop集群部署流程包括以下步骤:

-
首先需要部署Mysql和zookeeper,因为Hadoop需要依赖zookeeper,Hive元数据存储使用的是Mysql;
-
其次需要部署Hadoop,Hive
-
最后部署Spark,因Spark依赖hivemetastore
PS:部署顺序是不可逆的

-
选择需要部署的产品包,点击部署按钮,然后选择对应需要部署的集群,默认集群为dtstack,集群名称可配置;
-
下一步选择需要部署的服务,默认产品包下的服务都会部署,可以根据实际需求部署,在此阶段可以对服务的配置文件进行修改,例如:修改Mysql连接超时时间等;
-
最后点击部署,等待部署完成。
接下来我们以Mysql服务部署流程来为大家实际演示下整体流程:
● 第一步:选择集群
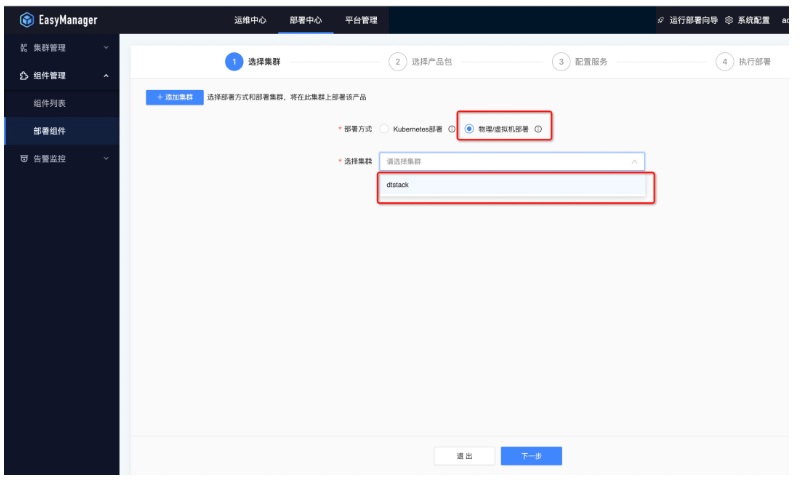
● 第二步:选择产品包
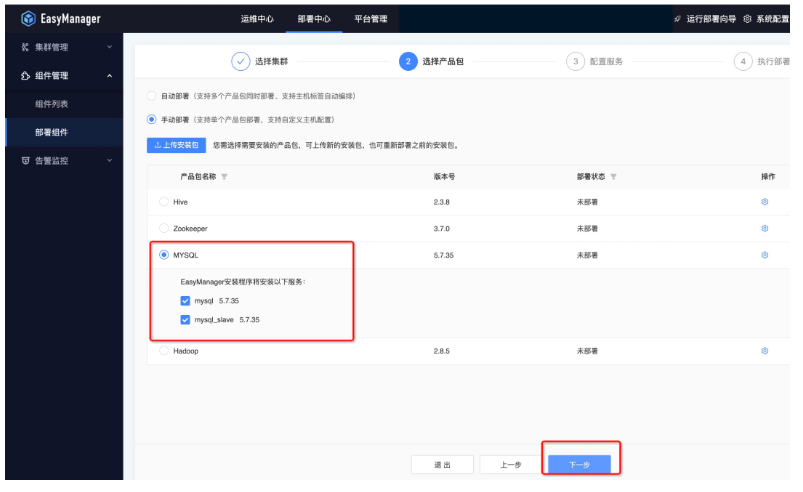
● 第三步:选择部署节点

● 第四步:部署进度查看
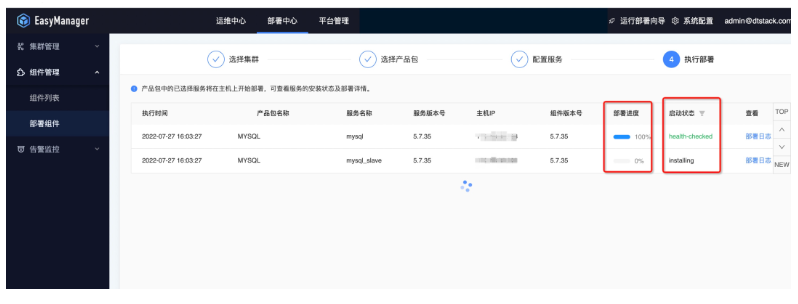
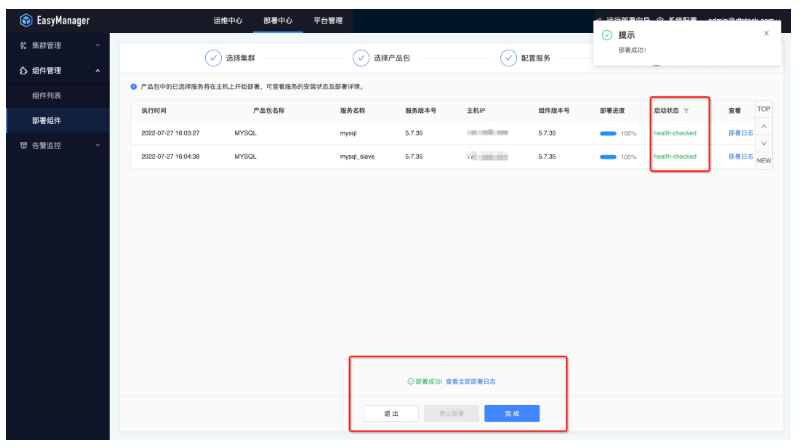
● 第五步:部署后状态查看
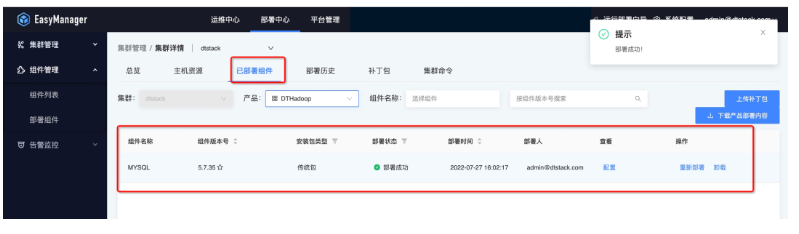
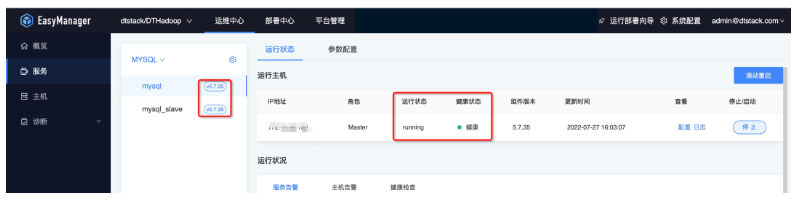
集群部署完毕后,若有需求可以进行配置变更操作。
● 配置修改
例如:如果需要操作修改yarn的配置文件,可以先选择yarn-site.xml文件,可以在搜索框搜索需要修改的配置文件key,如cpu_vcores。
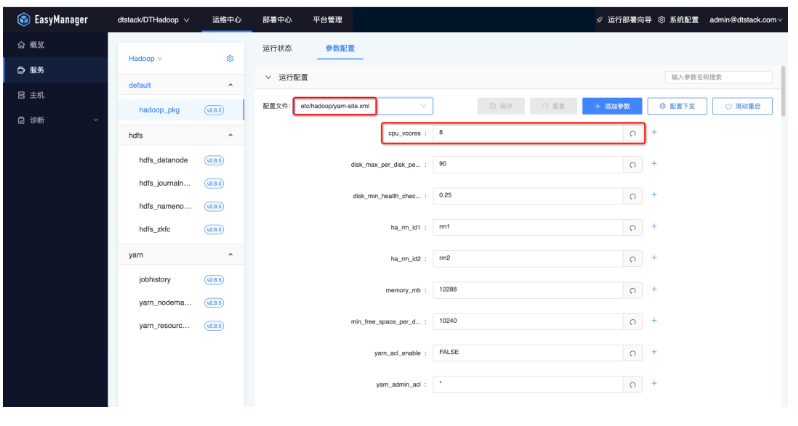
● 配置保存
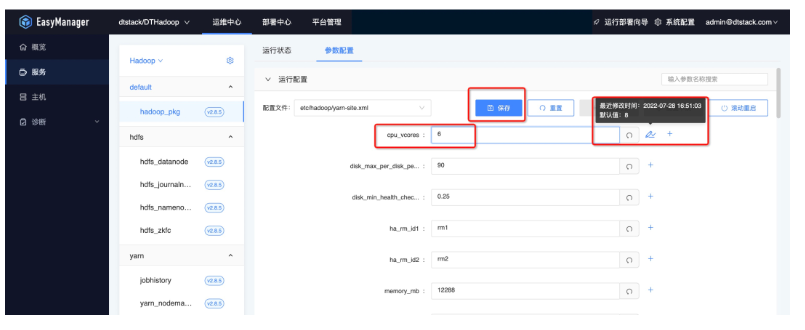
● 配置下发

ChengYing除了可自动部署运维外,还可以对接Taier部署Hadoop集群,Taier 是一个大数据分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
利用ChengYing部署管理Taier服务,可以做到实时监控Taier的服务状态,随时界面修改Taier配置等。Taier对接Hadoop集群的操作流程如下:

-
首先需要在Taier控制台选择多集群配置,新增一个集群;
-
然后配置sftp、资源调度组件、存储组件和计算组件;
-
配置完成后需要保存并且测试连通性。
注意事项:
在对接过程中,sftp主机需要和Taier网络相通,并且sftp配置主机的路径需要存在,如果不存在,需要手动创建。
Taier的部署网络需要与Hadoop网络相通,如果运行任务,需要在Taier所在节点加入Hadoop集群的Host配置;编译/etc/hosts文件,增加IP Hostname。
● 第一步:配置公共组件
首先进入Taier登陆界面,点击控制台,新增集群,然后进入多集群管理界面,配置公共组件,选择SFTP,进入SFTP配置界面。
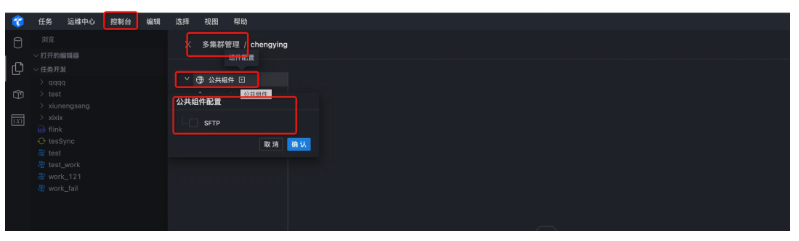
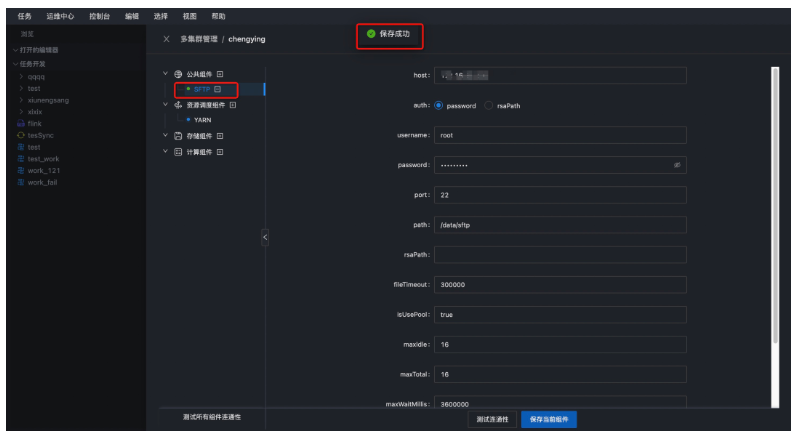
● 第二步:配置SFTP
然后配置SFTP的host,认证方式,默认采用用户名密码方式,输入用户名和密码,并且输入path路径,此路径需要在主机上存在,如果不存在,需要手动创建一个SFTP路径.
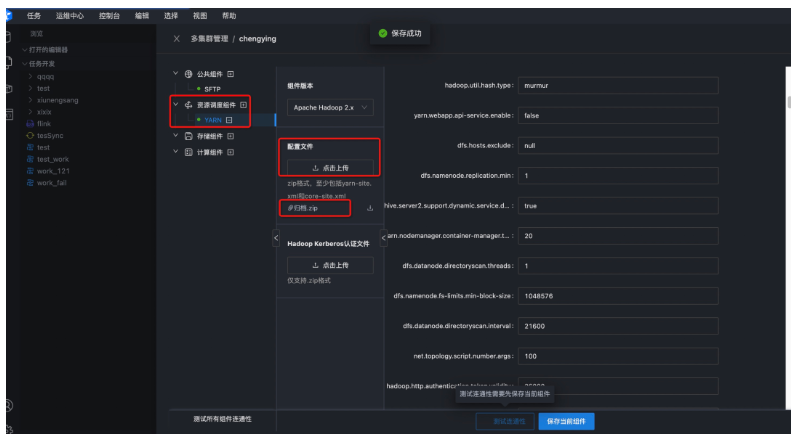
● 第三步:资源调度组件配置
需要到部署Hadoop服务器到/opt/dtstack/Hive/hive_pkg/conf目录下获取hive-site.xml文件,下载到本地;
到/opt/dtstack/Hadoop/Hadoop_pkg/etc/Hadoop目录下获取hdfs-site.xml、core-site.xml、yarn-site.xml文件,下载到本地;
这四个文件压缩成一个zip包,上传这个压缩包。
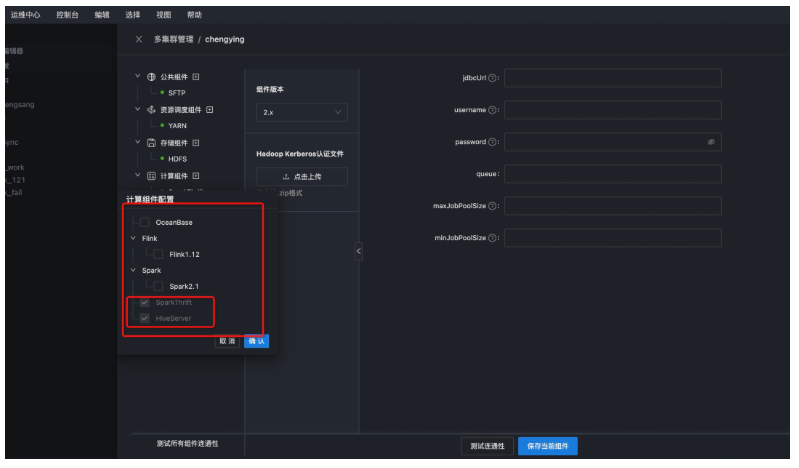
● 第四步:计算组件配置
选择计算组件模块,选择需要对接的计算引擎Hive和Spark,选择Hive和Spark的版本,填写对应的jdbc(jdbc:hive://ip:port/)连接串,然后点击保存,测试连通性。
注意:jdbcurl中ip分别为Hive组件的hiveserver2和Spark中的thrifterserver所在节点ip。
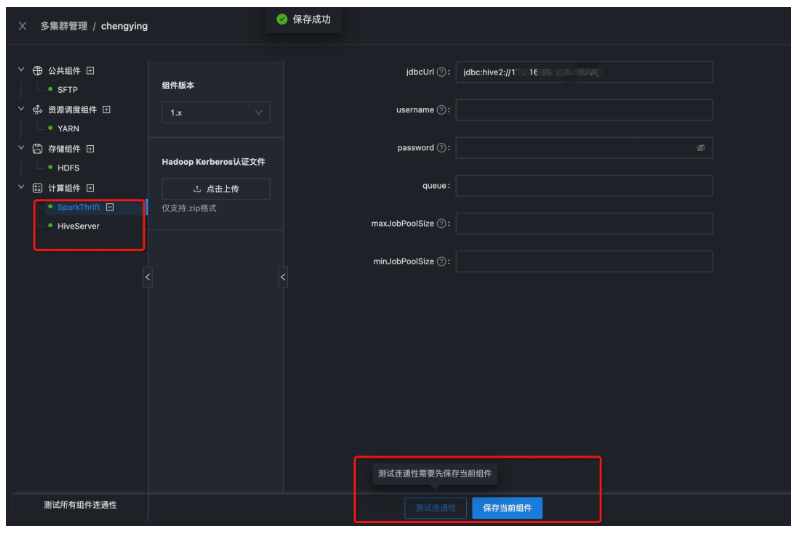
● 第五步:配置Hive和Spark
以下是配置完成Hive和Spark组件后,测试连通性的状态。
注意:本地演示环境Hadoop未开启安全,Hive和Spark只需要配置jdbcurl即可。
最后和大家聊聊Hadoop集群近期规划,近期主要有三大规划:
● 产品包制作
制作ChengYing部署产品包的流程及实践。
● ChunJun&Taier产品包
制作可以用ChengYing部署的Taier和chunjun的产品包
● Hadoop运维
通过ChengYing运维大数据集群;
通过ChengYing一键开启Hadoop集群安全。