

Hadoop的优势在于批处理,MapReduce并不特别适用于交互/特殊指定的查询。 实时(Real-time)1SQL查询(在Hadoop数据上)通常使用自定义连接器来执行MPP数据库。实际上这意味着在独立的Hadoop和数据库集群之间有连接器。在过去几个月中,一些提供快速的系统Hadoop集群中的SQL访问受到关注。 Hadoop和快速MPP数据库集群之间的连接器并没有消失,但是人们越来越感兴趣于将许多交互式SQL任务转移到与Hadoop共存于同一集群上的系统中。

拥有支持快速/交互式SQL查询的Hadoop集群可以追溯到几年前HadoopDB,一个来自耶鲁的开源项目。 HadoopDB的创建者此后开始了一家商业软件公司(Hadapt),旨在构建一个将Hadoop /MapReduce和SQL相结合的系统。在Hadapt中,(Postgres)数据库放置在Hadoop集群的节点中,形成一个系统2可以使用MapReduce、SQL和搜索(Solr)。从版本2.0开始,Hadapt是容错系统,具有分析功能(HDK),可以通过SQL使用。
开源系统本文的其余部分介绍了两个相对较新的开源工具:Impala和Shark。 自Strata NYC发布以来,Cloudera的Impala系统产生的嗡嗡声突出显示了大数据社区需要Hadoop中的实时查询系统的程度。自从发布以来,已经有许多关于Impala的优秀文章(参见这里和这里),所以这里不会深入涉及它的设计细节。我会强调一下Cloudera展现的令人印象深刻的性能数据。
对于纯粹的I/O绑定查询,我们通常会看到3-4倍范围内的性能提升。 …对于至少有一次连接的查询,我们已经看到7-45X的性能提升。 …如果通过查询访问的数据从缓存中提取出来,由于Impala的卓越效率,加速将更加激烈。在这些情况下,即使在简单的聚合查询中,我们也看到了Hive上20倍-90倍的加速。
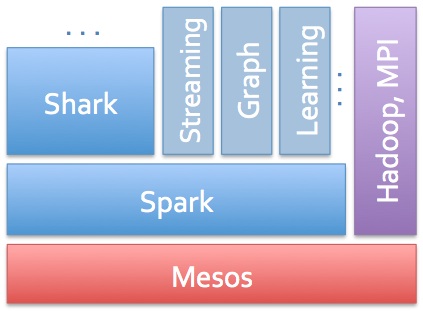
Shark Shark是一个Spark组件,一个开源的分布式和容错内存分析系统,可以安装在与Hadoop相同的集群上。特别是,Shark完全兼容Hive和支持HiveQL,Hive数据格式和用户自定义功能。另外Shark可以用来查询来自4在HDFS,Hbase和Amazon S3的数据。
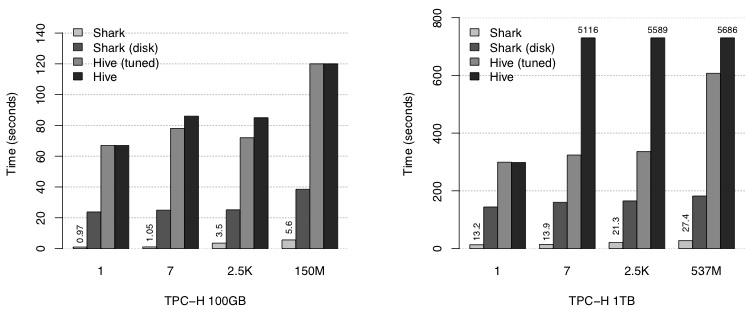
Shark的创作者刚刚发表了一篇论文,在文中他们系统地比较了它与Hive的表现,Hadoop和MPP数据库。他们发现Shark比Hive在各种查询上快得多:大概来说,Shark在磁盘上的速度要快5-10倍,而Shark内存模式的速度要快100倍。重要的是,Shark的表现收益是与MPP数据库中观察到的相当!
在这个阶段,用户至少有两个可用于Hadoop中快速/交互式SQL的开源系统。虽然Impala引起了更多的关注,但Shark团队已悄悄地将高扩展系统集成在一起,该系统具有引人注目的功能五包括数据联合分区(co-partitioning),容错(fault-tolerance)以及将机器学习(machine-learning)集成到分析师的工作流程中。
内存列存储和列压缩使用Impala时获得的最佳性能是通过使用Trevni列存储格式实现的。在Shark的情况下,他们的自定义列式存储和压缩将存储和查询时间缩短了大约5倍。
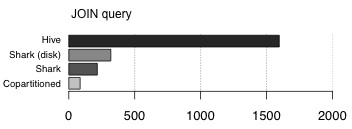
控制数据分区=>快速,分散式JOINSShark让用户使用指定的键分区表。特别是如果表经常是“joined”,那么可以使用通用(“join”)键对它们进行分区。 Co-partitioning是许多MPP数据库用来加速“joins”涉及大量表的技巧。
容错(Fault-tolerance)Shark可以从节点故障中优雅地恢复6,并且在重建丢失的(数据)分区之后继续执行查询。对大数据集的初始测试表明恢复对性能的影响很小(并且比re-executing查询快得多)。
SQL “optimizer”Shark已经实现了一个简单的优化器(部分DAG执行或PDE)使用数据统计(重击者,近似直方图)在需要时动态地改变查询计划。例如,Shark的PDE系统使用数据统计信息为“joins”执行run-time优化。
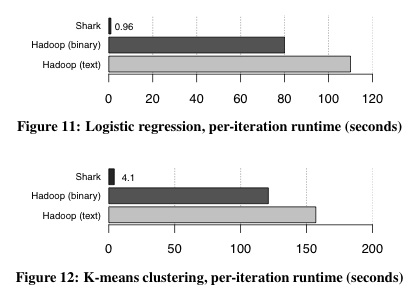
机器学习(Machine-learning)支持 RDD的是分散式可以缓存在跨计算节点集群内存中的对象。它们是Spark中使用的基本数据对象。用户可以创建RDD(使用sql2rdd命令)并将machine-learning函数应用于它们。目前machine-learning和分析函数可以用Scala和Java编写,并且即将支持Python。用户不仅可以从相同的内部获得执行简单SQL查询和复杂计算的好处7框架,而且Shark比Hadoop快100倍:
与BI工具集成Impala与Tableau和QlikView的。有Shark用户使用Tableau之类的工具,但BI集成是Shark内的相对未探索(“unexplored”)区域。
总结Impala和Shark是Hadoop的交互式SQL系统。一个新文章显示Shark提供加速与MPP数据库中观察到的相当。除了比Hive for SQL快100倍以外,Shark的框架比(迭代式)machine-learning算法的Hadoop快100倍。